Kévin – Mizu has openly provided his research papers on HTML parsing and the DOMPurify library. Let me simplify it for you and let us grasp this security research, which is essential for you to know and understand as a security researcher.

What Is DOMPurify And Why Is It Used ?
In order to prevent cross-site scripting (XSS) attacks, HTML sanitization—the process of eliminating dangerous code from user-generated content—is accomplished with the help of the JavaScript package DomPurify.

It removes potentially dangerous elements, attributes, and scripts while maintaining the HTML’s visual organisation and structure. To reliably render user-input data, such comments, social network feeds, or forms, without exposing the application to XSS vulnerabilities, web applications frequently employ DomPurify. By stopping harmful code from running, it contributes to the application’s security and integrity.

Quick Installation Guide
To begin installing the library, use the commands listed below.
npm install dompurify
npm install jsdomBasic Walkththrough Of Client Side HTML Sanitization ?
The researcher has provided an informative summary of how client-side HTML is sanitised in current applications in common online applications.
JavaScript libraries known as client-side HTML sanitisers examine and alter HTML code to stop harmful information from running on the client side. They accomplish this by removing or encrypting potentially dangerous components—like scripts, forms, and anchors—and substituting them with less dangerous ones.
Client-side sanitisers lessen the possibility of cross-site scripting (XSS) attacks, which risk user security and data, by accomplishing this. DOMPurify, js-sanitize, and sanitize-html are well-known client-side sanitisers that offer a variety of capabilities and customisations to accommodate varied use cases.
DOMPurify Working
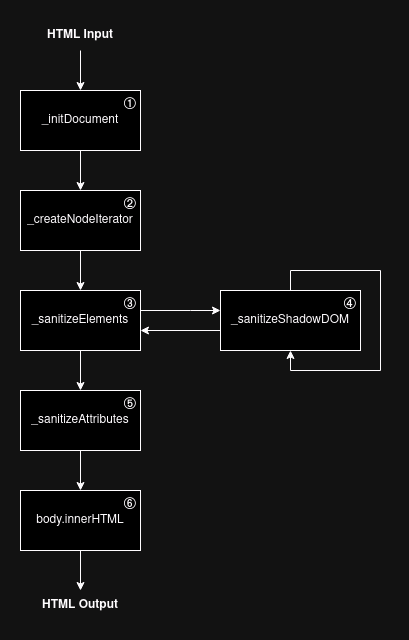
- _initDocument: Uses the DOMParser API to parse the HTML as the browser would.
- _createNodeIterator: Uses NodeIterator to iterate over the DOM tree.
- _sanitizeElements: Checks for DOM Clobbering, mXSS, etc., and ensures the current tag is allowed.
- _sanitizeShadowDOM: The NodeIterator API doesn’t iterate over the <template> tag by default. Recursively sanitizes when it reaches a DocumentFragment.
- _sanitizeAttributes: Sanitizes HTML attributes using DOM APIs.
- body.innerHTML: Serializes the clean HTML output and returns it.
What Is Mutation Xss ? What Is the reason for there occurence ?
When an attacker inserts anything that appears to be safe but is altered and changed by the browser during markup parsing, this is known as mutated XSS. Because of this, it is quite difficult to find or remove from the application logic of the website.
A list of discovered mutation techniques is provided by the researcher.
Understanding Node flattening

There are numerous things to take into account when processing an HTML tree. How deep a DOM tree may be is one feature that may not immediately come to mind. Curiously, there are no clear instructions on how to handle this in the HTML specification.
The way your browser handles it now is an example of how each HTML parsing implementation can establish its own limit and behave differently when it reaches it.


This clearly suggests that the flattening takes place following the parsing of the node. Consequently, a “invalid” HTML DOM tree could be produced, which, if serialised and processed again, would result in still another modification.
How HTML parse states are handled ?

HTML parsing involves splitting the HTML document into a document object model (DOM) or a parse tree. Regarding parsing states, HTML5 specifies a number of states that the parser may be in, such as:
- Initial state: When the parser comes across the beginning of the document, it begins in this state.
- Tag open state: When the parser comes across an element’s start tag, it is in this state.
- Tag closing state: When the parser comes across an element’s end tag, it is in this state.
- Character data state: When the parser comes across text or other character data, it is in this state.
- When the parser comes across a CDATA section, it is in the RCDATA state.
- State of raw text
Proof Of Concept : Bypassing
According to a researcher’s comment, Firefox is not vulnerable to this mutation since it does not mutate when a <table> is present at the same level as the second <caption> tag. But utilising deep nesting, @kinugawamasato found another mutation that affects Firefox, Chromium, and Safari.

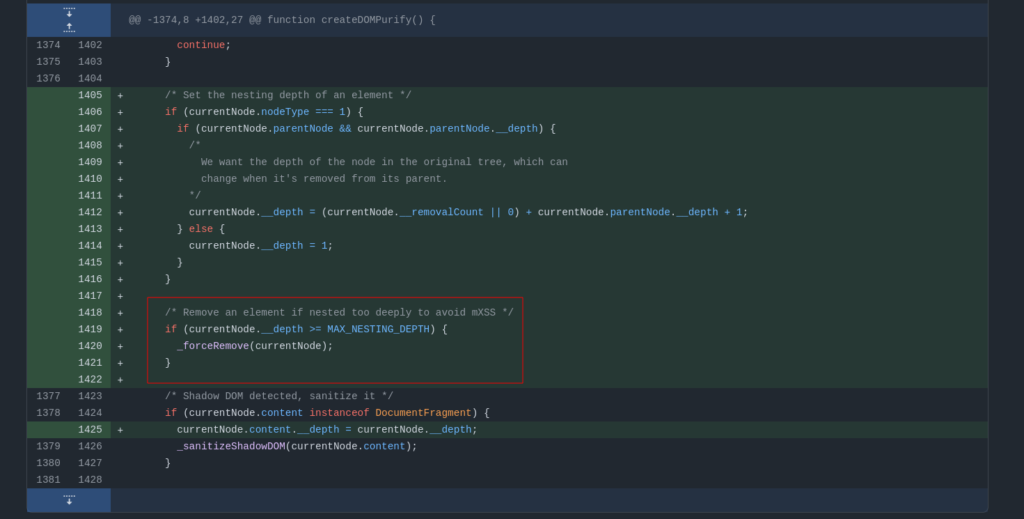
Fix for DOMPurify 3.1.0
With the assistance of @IcesFont, @cure53berlin resolved this problem by limiting the maximum nested depth to 255 using a custom depth counter. Obtain a node’s current depth using a browser API like due to the absence of such an API
More Can Be Read On

Four DOMPurify bypasses have been discussed in this article. As we have seen, HTML can be incredibly unpredictable due to a number of particular behaviours, like node flattening, insertion modes, and the stack of open elements, which can produce a variety of mutations that produce surprising outcomes.
Furthermore, even if the most recent DOMPurify update is reliable, it also means that a single regular expression is now mostly responsible for the library’s security.